


I don't know about you, but when I first encountered ChatGPT, I was blown away. I used it a few times, including to write a poem about SAML and OIDC.
Even though it got some of the details wrong, I was impressed.
But what I immediately thought of was what this could mean for technical documentation. Such documentation is critical for developer happiness. Have you ever fished through GitHub repositories, source code, discord or slack, and forums to find a solution to an obscure technical problem? I have, and it's no fun.
Seeing the ability of ChatGPT and the underlying large language model (LLM) to answer questions across a range of disciplines, I wanted to see what such a model could do with the FusionAuth corpus of over 300 docs, thousands of GitHub issues, and 2000+ forum posts. While I still believe most developers use Google as their primary documentation interface (ht Taylor Barnett), I wondered "could an LLM surface documentation better"?
The Startups Cometh
I initially looked at LangChain to build an interface to our documentation. But real life quickly intervened. Spending a bunch of time getting up to speed on building an LLM, as fun as it would be, was not a good use of my time.
There were a number of startups that thought the same, and built products and companies with the goal of applying LLMs to technical documentation. I looked around at one or two of them earlier this year, but there were issues. One choked on the number and size of documents we had, for example. I recall some of our docs were in asciidoc, not markdown, being an issue as well. And so I set it aside.
Then, I ran across Kapa, another startup which promised they could train a model on publicly available data as well as making it easy to access. They had integrations with both websites and Slack. Since almost all our documentation is available on the internet, I was interested.
We spun up a proof of concept and the FusionAuth team asked the LLM questions. It was pretty good.
I especially liked how their solution provided links to existing documentation. This, to me, is critical, because it alleviates hallucination worries. If you are using a LLM as a novel and helpful search interface for documentation, slightly wrong answers are less of an issue than if you are treating it as an oracle.
Rolling it out
We're rolling this AI assistant out to the wider FusionAuth community today. It's trained on the website, articles, technical documentation, forum posts, and blog posts right now. If the community finds this useful, we'll be adding it in other places, but for now you'll see it in the lower right hand side of the technical documentation sections.
Click or tap on it and type in your question. Using natural language is fine; this is one of the benefits of an LLM.

You'll see answers and the aforementioned links to supporting documentation.
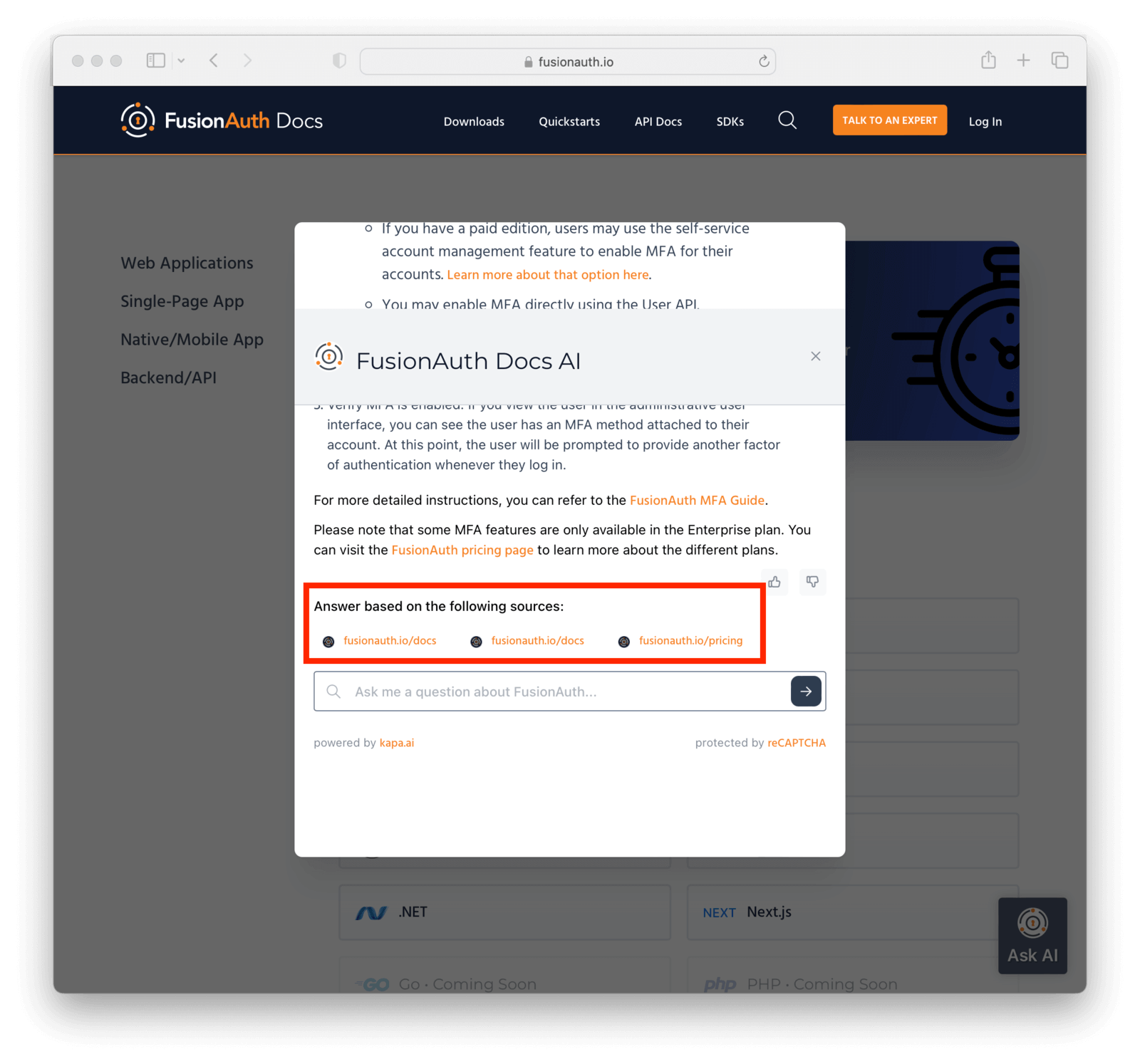
Go ahead. Ask your questions! We hope this will be of use as you learn more about authentication and FusionAuth.